จาก Push สู่ Production: Deployment Pipeline ของเราด้วย Argo CD
ตอนสร้างโปรดักต์ LMS (ระบบ Learning Management System คือซอฟต์แวร์จัดการการเรียนรู้ที่ช่วยองค์กรวางแผน ดำเนินการ และประเมินผลการฝึกอบรม มีทั้งแบบ Cloud-based และ Self-hosted...

ตอนสร้างโปรดักต์ LMS (ระบบ Learning Management System คือซอฟต์แวร์จัดการการเรียนรู้ที่ช่วยองค์กรวางแผน ดำเนินการ และประเมินผลการฝึกอบรม มีทั้งแบบ Cloud-based และ Self-hosted รองรับองค์กรทุกขนาด ตั้งแต่ Knowledge Management ไปจนถึงการพัฒนาทักษะพนักงาน)
คุณอยากให้ deployment pipeline ของคุณเป็น “สิ่งที่น่าเบื่อ”
ไม่ใช่เพราะการ deploy ไม่สำคัญ แต่เพราะมัน สำคัญเกินกว่าจะปล่อยให้ตื่นเต้น
เราคือ OpenMirai: สตาร์ทอัพที่กำลังสร้าง LMS ให้ผู้ใช้สามารถสร้าง organization ของตัวเองและเผยแพร่คอร์สได้ง่ายๆ นั่นแปลว่าเรา ship บ่อย แต่ก็ห้ามทำ flow การเรียน, การ publish, การชำระเงิน หรืออะไรก็ตามที่ creator พึ่งพาอยู่พังเด็ดขาด
ลองมาดูเรากันได้ครับ! https://openmirai.com
เราเลยสร้าง pipeline ที่ตั้งใจให้ “น่าเบื่อ” GitHub pull requests, GitHub Actions, Kubernetes และ Argo CD แยกระหว่าง staging กับ production
โพสต์นี้คือ walkthrough ว่าฟีเจอร์หนึ่งเดินทางจากเครื่อง developer ไปถึงผู้ใช้จริงได้ยังไง และทำไมเราถึงเลือกแบบนี้
เครื่องมือที่เราใช้
Stack หลักของเราหน้าตาประมาณนี้:
- Kubernetes สำหรับรัน service
- Argo CD สำหรับ GitOps-style deployment
- GitHub Actions สำหรับ CI และ automation
- GHCR (GitHub Container Registry) สำหรับ container image
- 2 environments: staging และ prod
นอกจากนี้เรายังใช้ feature flag ผ่าน PostHog สำหรับฟีเจอร์ที่เสี่ยงหรือยังเป็นช่วงต้น แต่นั่นเป็นอีกหัวข้อทั้งหัวข้อ (ไว้คุยกันในโพสต์ถัดๆ ไป)
ภาพรวมของ Flow
โค้ดเข้า staging ก่อน เราทดสอบและทำ regression ภายใน แล้วค่อย promote ไป production ในช่วง off-peak
มาแยกย่อยกันว่าจริงๆ มันเกิดอะไรขึ้นบ้าง และทำไม
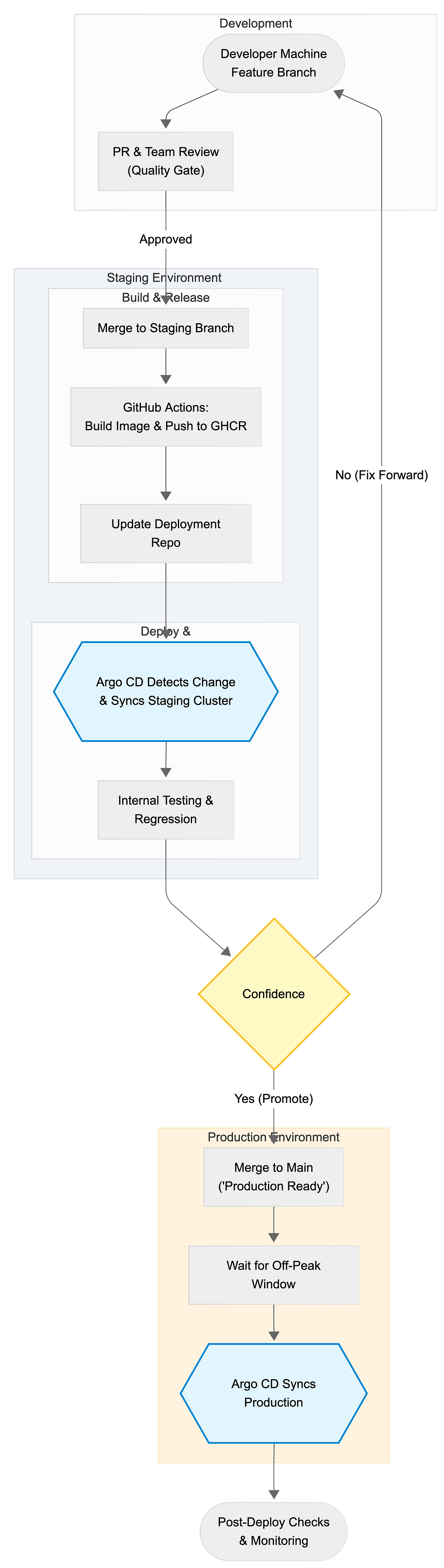
ขั้นที่ 1: Feature branch ทำให้ mainline สะอาด
ปกติเราเริ่ม Feature A จาก main (หรือบางครั้งจาก staging ขึ้นอยู่กับจังหวะ) แล้วทำงาน engineering ตามปกติใน branch แยก
Feature branch ไม่ได้เน้นเรื่อง “การแยกที่สมบูรณ์แบบ” แต่เน้นการให้เรามี unit ที่สะอาดสำหรับ:
- review การเปลี่ยนแปลง
- รัน CI
- เชื่อมโยงการสนทนากับโค้ด
- ตัดสินใจว่าเราพร้อม ship หรือยัง
ขั้นที่ 2: PR review คือ “quality gate” แรกของเรา

เมื่อฟีเจอร์พร้อม เราเปิด PR แล้ว review กันเป็นทีม
ส่วนนี้ถูก underrated มาก PR review คือจุดที่ความเสี่ยงโดนจับได้ตั้งแต่เนิ่นๆ:
- side effects ที่ไม่ได้ตั้งใจ
- migration ที่ลืมใส่
- edge case ในเรื่อง permission
- ช่องโหว่แบบ “works on my machine”
- การปรับปรุง test และ observability
เราไม่มอง PR เป็น bureaucracy แต่มองมันเป็น ช่วงเวลาเงียบๆ ครั้งสุดท้าย ก่อนที่เราจะนำการเปลี่ยนแปลงเข้าสู่ environment ที่ใช้ร่วมกัน
ขั้นที่ 3: Merge เข้า staging (ไม่ใช่ production)

หลังจาก PR ผ่าน เรา merge เข้า staging
เป็นการออกแบบที่ตั้งใจ staging คือ integration environment ของเรา เป็นที่ที่ “โค้ดเจอความจริง”: service จริง, dependency จริง, config จริง, network path จริง
ถ้ามีอะไรจะพังใน Kubernetes เราอยากให้มันพังที่ staging
ขั้นที่ 4: GitHub Actions build และ push image
เมื่อโค้ดเข้า staging แล้ว GitHub Actions ทำเรื่องซ้ำๆ ที่มนุษย์ไม่ควรต้องทำ:
- build container image
- tag (เราชอบใช้ immutable reference เช่น sha-256)
- push ไป GHCR
นี่คือเหตุผลหนึ่งที่ container-based delivery ดี เรา deploy artifact ไม่ใช่ “อะไรก็ตามที่บังเอิญอยู่บน VM”
ขั้นที่ 5: GitOps ด้วย deployment repository เดียว
เรามี repository แยกสำหรับ deployment ภายในทีมเรียกว่า openmirai deploy
repo นี้เก็บ Kubernetes manifests (หรือ kustomize/helm config) ของเรา และมันคือ source of truth ว่าอะไรกำลังรันอยู่ใน environment ไหน
จุดสำคัญอยู่ตรงนี้:
GitHub Action ของเราอัปเดต deployment config โดยการเขียน image SHA ใหม่ลงในไฟล์ Kubernetes deployment ที่เกี่ยวข้อง
แทนที่จะ “push” deployment เรา commit desired state
นั่นแปลว่า:
- คุณมองเห็นทุก deploy เป็น git diff
- การ rollback คือ git revert
- Argo CD แค่ทำตามสิ่งที่อยู่ใน git
และยังหมายความว่า Argo CD ไม่ต้องการการแทรกแซงพิเศษจากมนุษย์สำหรับ staging
ขั้นที่ 6: Argo CD auto-deploy ไป staging
Argo CD เฝ้าดู deployment repository อย่างต่อเนื่อง
เมื่อมันเห็นการเปลี่ยนแปลง เช่น image SHA ใหม่ มันจะ reconcile cluster ให้ตรงกับสิ่งนั้น
flow เลยกลายเป็น:
git commit → Argo CD sync → pods roll → staging updated
นี่คือสิ่งที่เราชอบเกี่ยวกับ GitOps มันเปลี่ยน deployment ให้กลายเป็น “การเปลี่ยนแปลง repository ที่ controlled และ auditable” แทนที่จะเป็นพิธีกรรมทำมือ
ขั้นที่ 7: Internal testing และ regression ใน staging
เมื่อเวอร์ชันใหม่ live บน staging แล้ว เราทำ internal testing:
- happy path checks
- regression checks (เรื่องที่มักจะพัง)
- sanity check เรื่อง performance หรือ error ที่ spike
- บางครั้งทำ “dogfooding” สั้นๆ ในทีม
ถ้าเรายังไม่มั่นใจ เราไม่ promote เรา fix forward แล้วทำซ้ำ
ถ้าฟีเจอร์ยังเป็นช่วงต้น เสี่ยง หรือตั้งใจเปิดให้ผู้ใช้บางกลุ่มเท่านั้น เราจะ ship หลัง feature flag (PostHog) เพื่อให้โค้ดอยู่ใน prod ได้โดยที่ยังไม่เปิดให้ทุกคน
ขั้นที่ 8: Merge เข้า main เมื่อมั่นใจเท่านั้น
เมื่อ staging ดูดีแล้ว เรา merge เข้า main
นี่คือขั้น “promote codebase” ของเรา
เราเรียนรู้ว่า การปฏิบัติต่อ main ในฐานะ “สิ่งที่เราเชื่อว่า production-ready” ทำให้ทีมสอดคล้องกัน และยังทำให้ hotfix และ rollback วุ่นวายน้อยลง
ขั้นที่ 9: Production deploy ตั้งเวลาในช่วง off-peak
Production deployment ของเราเกิดในช่วง off-peakโดยทั่วไปคือ 23:00–01:00
ส่วนหนึ่งคือลดผลกระทบต่อผู้ใช้ แต่อีกส่วนคือให้เราเองมีหน้าต่างเงียบๆ ในการเฝ้าดูการ release
ใช่ continuous deployment แบบ auto นั้นเท่ แต่ทีมช่วงต้นไม่ได้ต้องการ “ship เมื่อไหร่ก็ได้” เสมอไป บางครั้งสิ่งที่ต้องการคือ “ship อย่างปลอดภัย”
เราเลยเลือก production release ที่ตั้งใจ ในเวลาที่คาดเดาได้
ขั้นที่ 10: Post-deploy checks

หลังจาก deploy production เราทำ post-check:
- key user flow (login, เข้าคอร์ส, ซื้อ/publish)
- dashboard เรื่อง service health
- error rate และ log
- alert จาก monitoring
ส่วนนี้น่าเบื่อ และนั่นแหละคือเหตุผลที่มันได้ผล
ทำไม pipeline แบบนี้ถึงเหมาะกับเรา
หลักการที่เรา optimize ตามมีไม่กี่ข้อ:
1) Staging คือที่ของ surprise เราอยากเจอปัญหาภายใน ดีกว่าเจอผ่านข้อความจากลูกค้า
2) Git คือประวัติ deployment ทุกการเปลี่ยนแปลงคือ diff การ rollback ง่าย การ audit ก็ง่าย
3) Automation จัดการเรื่องน่าเบื่อ มนุษย์ตัดสินใจ เครื่องจักร build artifact และอัปเดต manifest
4) Production release เป็นเรื่องตั้งใจ เรา ship บ่อย แต่ยังคงขั้น “promote” ที่ชัดเจน และ deploy ในช่วงเวลาเงียบ
สิ่งที่เราจะปรับปรุงต่อ
แม้แต่ pipeline ที่ “น่าเบื่อ” ก็ยังต้องวิวัฒนาการ มีบางจุดที่เรากำลังคิดอยู่:
- automated regression check ที่ดีกว่านี้
- canary หรือ progressive delivery สำหรับบาง service
- visibility มากขึ้นว่า “อะไรเปลี่ยน” ใน deploy แต่ละครั้ง
- การเชื่อม feature flag กับ deployment ให้แน่นขึ้น
และใช่ feature flag สมควรมีโพสต์ของตัวเอง โดยเฉพาะวิธีที่เราใช้ PostHog เพื่อลดความเสี่ยงในขณะที่ยัง ship ตั้งแต่เนิ่นๆ ได้
ปิดท้าย
Deployment pipeline ไม่ใช่แค่ diagram ของ DevOps มันคือ product decision
สำหรับเรา GitHub Actions + GHCR + deployment repo เดียว + Argo CD ให้เส้นทางที่ชัดเจนและไม่กดดันจาก push ไปสู่ production โดยไม่ทำให้การ deploy กลายเป็น “hero activity”
ถ้าคุณกำลังสร้างโปรดักต์แบบ multi-tenant ที่ความน่าเชื่อถือสำคัญ ผมแนะนำเลยว่า เก็บ pipeline ของคุณให้น่าเบื่อเข้าไว้
Boring ships.